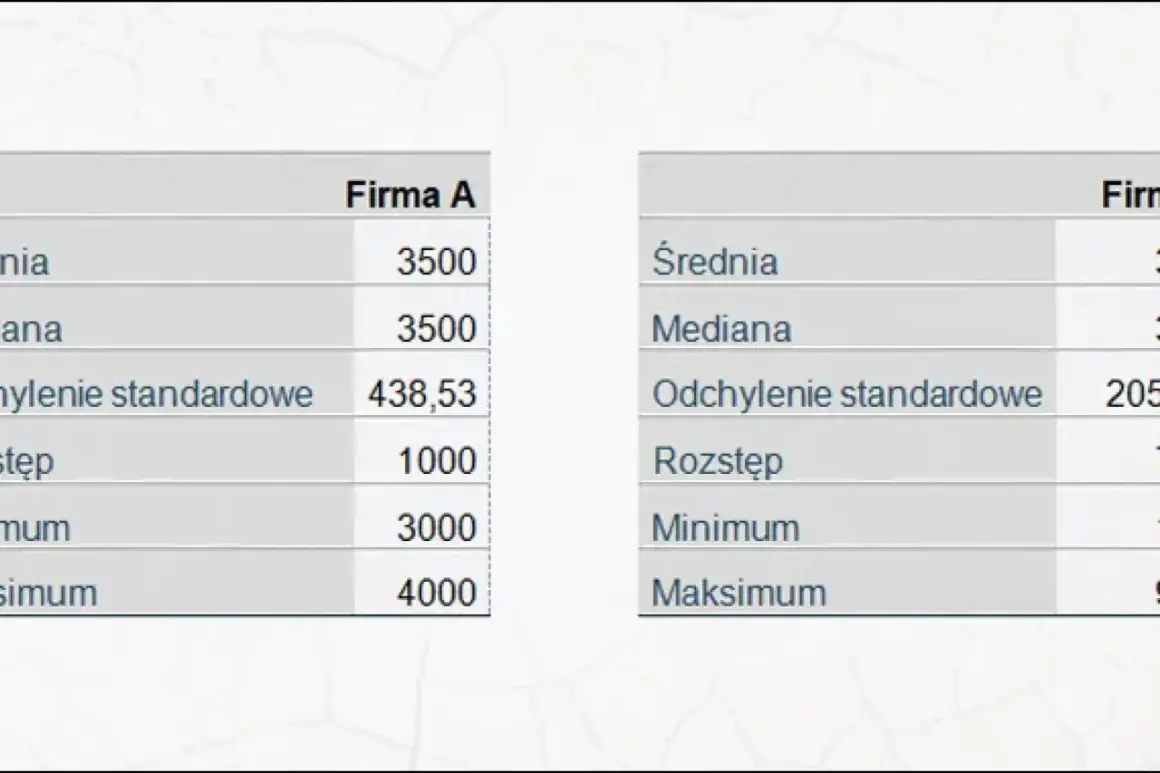
Rozproszenie danych mówi często więcej niż sama średnia. W statystyce wariancja pokazuje, czy wyniki trzymają się blisko siebie, czy rozchodzą się szeroko, a w naukach przyrodniczych pomaga odróżnić realną zmienność zjawiska od zwykłego szumu pomiarowego. W tym tekście wyjaśniam, jak ją czytać, liczyć i interpretować tak, żeby liczby faktycznie pomagały w pracy z danymi.
Najważniejsze rzeczy o rozproszeniu danych
- Im bardziej wyniki są do siebie podobne, tym niższe rozproszenie; gdy wartości mocno się różnią, miara rośnie.
- Skala zaczyna się od 0 i nie ma górnej granicy.
- Do całej populacji i do próby stosuje się inny mianownik, więc ten sam zbiór może dać trochę inny wynik.
- W badaniach przyrodniczych ta informacja pomaga odróżnić naturalną zmienność od błędu pomiaru.
- Wynik jest w jednostkach do kwadratu, dlatego do opisu dla człowieka często wygodniejsze jest odchylenie standardowe.
- Najlepszy wniosek daje połączenie średniej, rozproszenia i spojrzenia na pojedyncze obserwacje.
Czym ta miara mówi o wynikach pomiarów
W praktyce traktuję ją jako odpowiedź na pytanie: „jak bardzo wyniki uciekają od środka?”. Jeśli wszystkie obserwacje są identyczne, rozproszenie wynosi 0. Im mocniej wartości skaczą wokół średniej, tym wynik rośnie.
To ważne zwłaszcza w biologii, ekologii i chemii, gdzie dwie próby mogą mieć taką samą średnią, ale zupełnie inną stabilność. Jedna może być skupiona wokół jednego poziomu, druga może zawierać mieszankę wartości niskich i wysokich - i właśnie to rozróżnienie często zmienia wniosek z badania.
Nie interpretuję tego wyniku jako „dobrego” albo „złego” samym w sobie. On po prostu mówi, czy dane są spójne, czy chaotyczne, a dopiero kontekst podpowiada, skąd ta różnica się bierze. Kiedy już to widzisz, naturalnym krokiem jest policzenie miary na konkretnym zbiorze liczb.
Jak policzyć ją krok po kroku
Najpierw warto rozróżnić dwa przypadki. Gdy liczysz całą populację, dzielisz przez N. Gdy pracujesz na próbie, zwykle dzielisz przez n - 1, bo to lepiej szacuje rzeczywistą zmienność populacji. To drobny szczegół, ale w praktyce robi różnicę.
| Sytuacja | Wzór | Kiedy stosować |
|---|---|---|
| Populacja | σ² = Σ(xᵢ - μ)² / N |
Gdy masz wszystkie interesujące Cię wartości |
| Próba | s² = Σ(xᵢ - x̄)² / (n - 1) |
Gdy dane są tylko fragmentem większej całości |
Przykład. Załóżmy, że mierzę 8 wyników temperatury gleby w stopniach Celsjusza: 2, 4, 4, 4, 5, 5, 7, 9. Średnia wynosi 5, a odchylenia od średniej to: -3, -1, -1, -1, 0, 0, 2, 4. Po podniesieniu do kwadratu dostaję: 9, 1, 1, 1, 0, 0, 4, 16, czyli łącznie 32.
| Etap | Wynik |
|---|---|
| Suma kwadratów odchyleń | 32 |
| Miara dla populacji | 32 / 8 = 4 |
| Miara dla próby | 32 / 7 ≈ 4,57 |
| Odchylenie standardowe dla populacji | 2 |
Jeśli dane były w °C, sam wynik ma jednostkę °C², dlatego do intuicyjnego opisu częściej sięga się po odchylenie standardowe. W przyrodzie właśnie taka dodatkowa warstwa informacji często bywa ważniejsza niż sam przeciętny wynik.
Jak odczytywać ją w badaniach przyrodniczych
W naukach przyrodniczych niski wynik zwykle oznacza, że badane zjawisko jest względnie stabilne albo że pomiary są powtarzalne. Wysoki wynik nie musi od razu oznaczać problemu - czasem pokazuje po prostu naturalną zmienność środowiska, sezonu albo osobników.
W terenie spotykam trzy typowe sytuacje:
- Biologia - wysokość roślin na dwóch poletkach może mieć tę samą średnią, ale na jednym rośliny są podobne do siebie, a na drugim skrajnie różne. To sugeruje inne warunki wzrostu.
- Ekologia - liczba osobników w kolejnych próbnych odcinkach bywa nierówna, bo populacje rzadko rozkładają się idealnie równomiernie.
- Geografia i klimatologia - temperatura, opady czy wilgotność potrafią zmieniać się skokowo, więc sam poziom średni nie wystarcza do oceny miejsca lub okresu.
Tu ważna jest ostrożność: duży rozrzut może oznaczać realną różnorodność, ale może też wynikać z pojedynczego błędu pomiaru albo zbyt małej liczby obserwacji. Jeśli chcę wyciągnąć sensowny wniosek, patrzę równocześnie na metodę zbierania danych, wielkość próby i ewentualne obserwacje odstające. To prowadzi prosto do porównania z odchyleniem standardowym, które jest wygodniejsze do codziennego czytania liczb.
Czym różni się od odchylenia standardowego
To para pojęć, którą łatwo pomylić, ale ich rola jest trochę inna. Rozproszenie liczone w kwadratach świetnie nadaje się do obliczeń statystycznych, natomiast pierwiastek z tej wartości wraca do oryginalnej jednostki i jest czytelniejszy dla człowieka.
| Miara | Co pokazuje | Jednostka | Kiedy jest wygodna |
|---|---|---|---|
| Miara w kwadratach | Siłę rozproszenia wokół średniej | Jednostka² | Do obliczeń, modeli i testów statystycznych |
| Odchylenie standardowe | Typową odległość od średniej | Taka sama jak w danych | Do raportu, prezentacji i szybkiej interpretacji |
Ja zwykle używam obu, ale nie w tej samej roli. Jeśli chcę zrobić obliczenia, zostaję przy miarze kwadratowej. Jeśli chcę opowiedzieć o wyniku komuś, kto nie siedzi w statystyce, łatwiej powiedzieć, że obserwacje „odstają przeciętnie o około 2 jednostki”, niż tłumaczyć wartość w kwadratach.
Jeżeli porównujesz dane w różnych jednostkach albo na bardzo różnych skalach, sam wynik może być mylący. W takich sytuacjach lepiej spojrzeć jeszcze na współczynnik zmienności, czyli miarę względną, która pokazuje rozrzut w odniesieniu do średniej. Dzięki temu porównanie przestaje być sztuczne. A skoro już mowa o porównaniach, najwięcej pomyłek pojawia się właśnie wtedy, gdy ktoś czyta tę liczbę zbyt dosłownie.
Najczęstsze błędy przy interpretacji danych
- Mieszanie próby z populacją - użycie złego mianownika zawyża albo zaniża wynik.
- Ignorowanie jednostek - wartość w kwadratach nie jest tym samym co wynik w oryginalnych danych.
- Patrzenie tylko na jedną liczbę - średnia bez informacji o rozproszeniu potrafi ukryć ważne różnice.
- Zbyt mała próba - kilka obserwacji wystarczy do ćwiczenia, ale nie zawsze do sensownego wniosku o zjawisku.
- Przecenianie jednego odstającego punktu - pojedyncza nietypowa obserwacja może mocno podbić rozproszenie, ale nie zawsze oznacza realną zmianę w środowisku.
- Mylenie naturalnej zmienności z błędem - w przyrodzie część „szumu” jest normalna i nie da się jej całkiem wyzerować.
Jeśli mam doradzić jedną rzecz, to tę: zanim wyciągniesz wniosek, narysuj dane albo przynajmniej spójrz na ich układ w szeregu. Sama liczba bywa zaskakująco mało mówiąca bez obrazu całego zbioru. Dzięki temu ostatni krok staje się dużo bezpieczniejszy.
Zanim wyciągniesz wniosek z pomiarów terenowych
W danych z natury nie szukam idealnej gładkości, tylko sensu. Gdy średnia i rozproszenie idą w parze, łatwiej ocenić, czy badany obiekt jest stabilny, czy po prostu różni się w różnych miejscach albo momentach pomiaru.
Jeśli mam zostawić jedną praktyczną zasadę, brzmi ona tak: nie oceniaj jakości danych wyłącznie po średniej. Sprawdź rozrzut, wielkość próby, jednostki i odstające obserwacje, a dopiero potem formułuj wniosek. Wtedy liczby zaczynają opowiadać prawdziwą historię zjawiska, a nie tylko jego uśredniony cień.